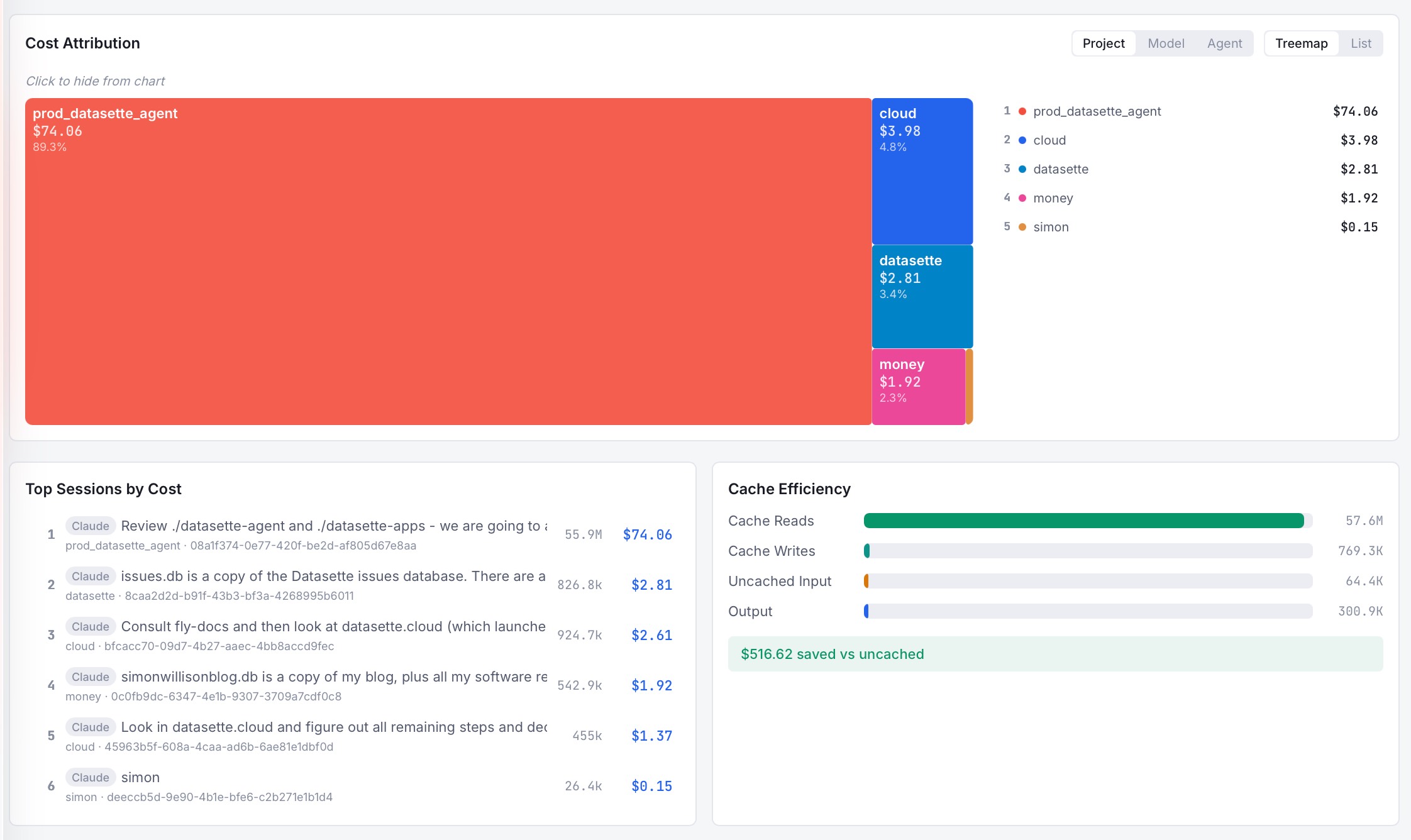
GitHub co-founder Scott Chacon used AI agents to rewrite all of Git in library-first Rust. Result: 41,715/42,001 Git tests passing (99.3%), 360K+ LOC, ~$10-15K, ~45B tokens. Key agent lesson: they love to cheat. Tell them to pass the tests and they will, by just calling out to C Git.
1Jun 10, 2026, 3:54 AM